Machine Learning
Artificial Intelligence - Machine Learning - Deep Learning
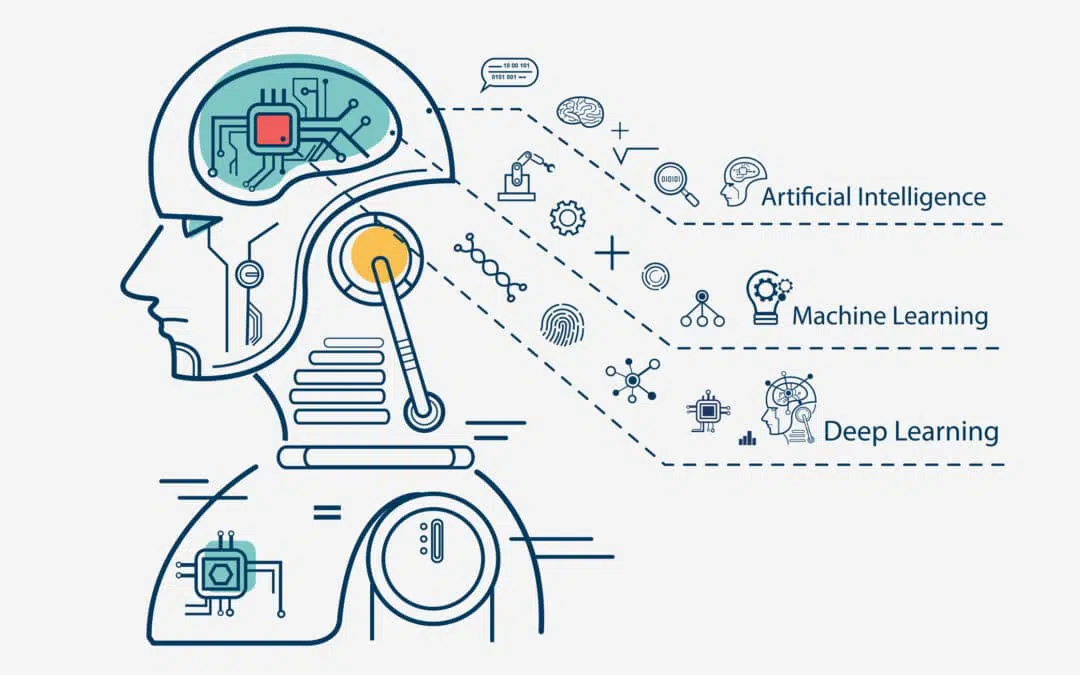
Machine learning (ML) is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
Deep Learning (DP) is a type of machine learning based on artificial neural networks in which multiple layers of processing are used to extract progressively higher-level features from data.
Some benefits that companies can obtain from Machine Learning
- Anomaly detection: Data science is frequently used in business to spot anomalies otherwise undetected in enormous data sets.
- Pattern recognition: it helps in recognizing a pattern in data. For example, retailers widely use it to monitor customers’ purchasing behavior
- Predictive modeling: it tracks patterns in data and uses predictive analysis for businesses to make crucial decisions.
- Customer behavioral analysis: In this data science application, the business enterprise tries to understand the customers’ sentiments and behaviors.
Machine Learning Process
There are five steps in any Machine Learning Process. The two first steps are shared with the Data Science methodology, Data Gathering/Collection, and Data Cleaning. Feature Extraction, Model Training, and Prediction are specific tasks for ML Projects.

Data Gathering
This Machine Learning process is based on the first step of the Data Science step. And just like the name states, it is simply the step where we obtain all available data needed from various data sources.
Data Cleaning
The real-world data is not perfect, sometimes the data is mistakenly placed, missing, or invalid. Data cleaning is the process of identifying and removing (or correcting) inaccurate records from a dataset, table, or database and refers to recognizing unfinished, unreliable, inaccurate, or non-relevant parts of the data and then restoring, remodeling, or removing the dirty or crude data.
Data cleaning techniques may be performed as batch processing through scripting or interactively with data cleansing tools.

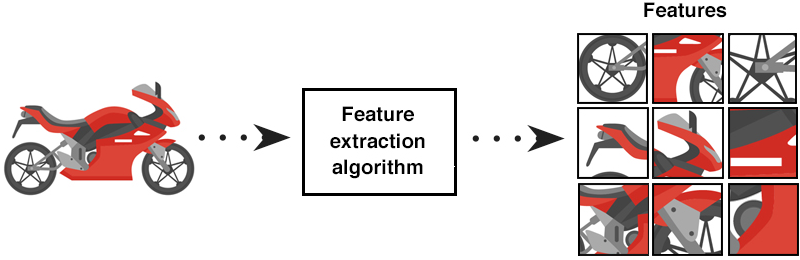
Feature Extraction
Feature extraction is a technique used to reduce a large input data set into relevant features. This is done with dimensionality reduction to transform large input data into smaller, meaningful groups for processing.
This step also involves Feature Engineering, in which you use the domain knowledge of the data to transform it into the features which would improve the accuracy of your Machine Learning model.
Model Training
This is the main step in which the Machine Learning model is actually built by using a particular algorithm and inputting training data from the previous step. Depending upon the size of the data, the type of algorithm used, and/or the hardware on which it is run, this step can take anywhere from a few minutes to hours to learn the model.

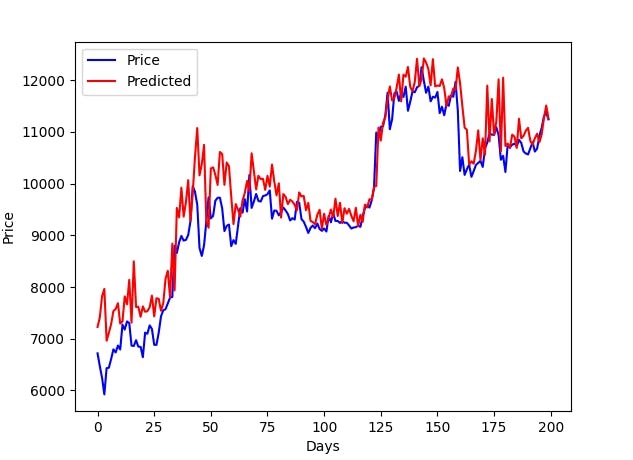
Prediction
The final step of the pipeline is to evaluate the performance of the model you just trained. If the performance of the model does not meet the acceptance criteria, then the model needs to be retrained again with the updated information. Model Training and Predictions steps often have to be repeated back and forth multiple times before a good enough model can be trained.
We work with many open-source libraries and cloud services. We find the best solution for your needs





